110 problems from 86 repositories selected within the current time window.
You can adjust time window, modifying the problems' release start and end dates. Evaluations highlighted in red may be potentially contaminated, meaning they include tasks that were created before the model's release date. Evaluations highlighted in orange display evaluations of external systems for reference. If a selected time window is wider than the range of task dates a model was evaluated on, the model will appear at the bottom of the leaderboard with N/A values.
Insights
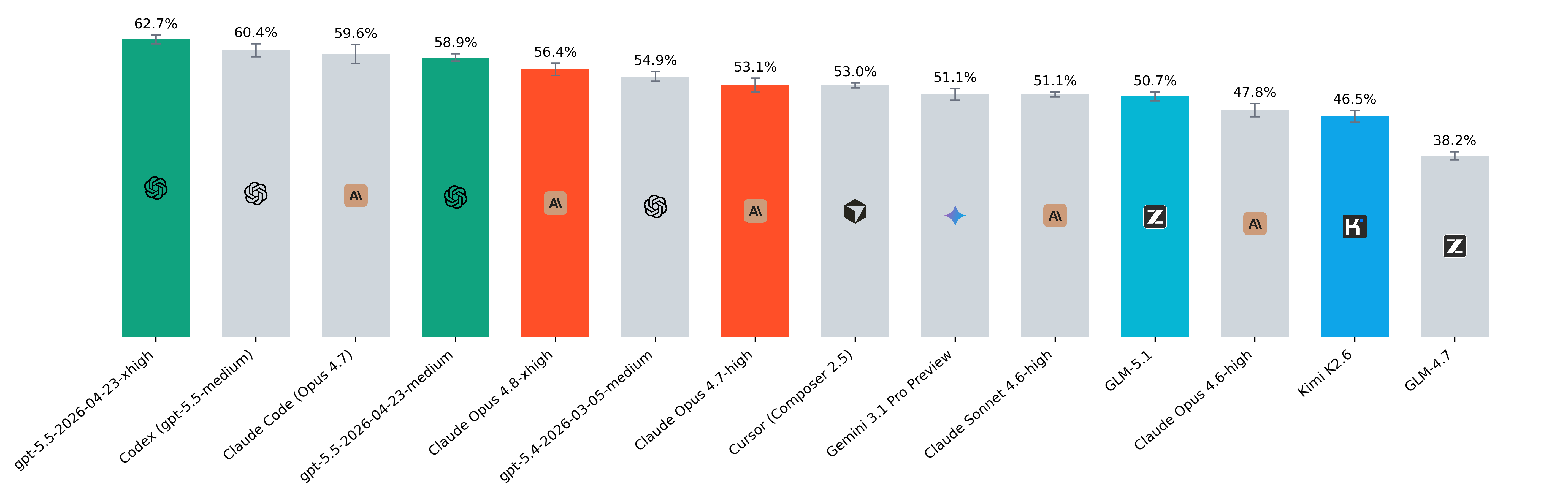
May 2026
- Cursor's Composer 2.5 has entered the top tier with an incredible cost-efficiency ratio of $0.23 per problem.
- We found that when tasks are provided to coding harnesses such as Claude Code, Codex, and Cursor in a standard issue format, the model may treat the task as ambiguous or informational rather than actionable. As a result, some runs complete without producing an actual code patch or diff. To address this, we added an explicit instruction prompting the model to always make a meaningful, valuable change when appropriate. This significantly reduced the number of empty patches produced by the harnesses.
- Claude Code methodology: We follow Anthropic’s default guidance and run in headless mode:
--model=claude-opus-4-7 --allowedTools="Bash,Read,Write,Edit" --bare --append-system-prompt='Always implement fixes by directly editing files using the Edit tool. Do not just analyze or propose solutions as text.' --output-format stream-json --verbose. - Codex methodology: We run Codex with gpt-5.5 as the primary model:
--model=gpt-5.5 -c features.web_search_request=false -c model_reasoning_effort=medium -c instructions='Always implement fixes by directly editing files using the Edit tool. Do not just analyze or propose solutions as text.' --yolo --json. - Cursor methodology: We run Cursor with Composer 2.5 as the primary model:
-p --force --output-format=stream-json --model=composer-2.5 --approve-mcps --endless-retries.
February 2026
We made some meaningful changes in the methodology:
- Removed demonstrations. Modern models don't need them anymore, since they can plan tasks and follow tool call formats well.
- Removed the strict limit of 80 steps. New models successfully work with big contexts and do not get stuck in endless loops, so the limit became just a hindrance, not a protection. For now, there is only one model limitation: a 128k context window.
- Added auxiliary interfaces. For some tasks (marked by _interface suffix) there are now provided names, signatures and descriptions of functions which are explicitly called by tests. This helps evaluate larger tasks fairly, ensuring valid solutions don't fail just because of mismatched test calls.
Key Takeaways:
- Claude Opus 4.6 and GLM-5 are highly consistent (34 and 30 tasks solved 5/5, 40 Pass@5 each), with top models separated by small gaps. DeepSeek-V3.2 has broad coverage (42 Pass@5, like gpt-5.2) but is less stable (24 tasks 5/5) and relies on heavier search (~3.05M tokens, ~84 turns per problem). Claude Opus 4.6 outperforms Sonnet 4.6 not by coverage, but by higher reliability on the same tasks.
- GPT-5.4 demonstrates further improvement in tokens efficiency, being among top 5 but with the lowest token number.
- Qwen3-Coder-Next and Step-3.5-Flash are the clearest examples on this leaderboard of models that seem to benefit from very large working context. Qwen3-Coder-Next is the extreme case: it averages about 8.12M tokens per problem, with roughly 154 turns on average. Step-3.5-Flash shows the same pattern in a milder form: about 3.73M tokens per problem and roughly 98 turns on average.
- DeepSeek-V3.2 and Qwen3-Coder-480B-A35B-Instruct reused much less cached context than most other models in our setup. The most likely reason is that vLLM was under heavy KV-cache memory pressure, so cached prefixes were often dropped and had to be rebuilt instead of reused.
- Claude Code, Codex, and Junie behave differently from SWE-style agents. They may ask clarifying questions, wait for confirmation, or produce conversational responses instead of making a code change, which can cause a fully automated run to stop without producing any patch. We explicitly disable internal web search for Claude Code and Codex; Junie does not yet support an equivalent flag, so we manually verified that the included instances did not rely on web search beyond the task's original GitHub repository.
- Claude Code methodology: We follow Anthropic’s default guidance and run in headless mode:
--model=opus --allowedTools="Bash,Read,Write,Edit" --permission-mode acceptEdits --output-format stream-json --verbose. We also setANTHROPIC_DEFAULT_OPUS_MODEL=claude-opus-4-6to use Opus 4.6 as the primary model. - Codex methodology: We run Codex with gpt-5.4 as the primary model:
--model=gpt-5.4 -c features.web_search_request=false -c model_reasoning_effort=medium --yolo --json. - [Update] - We re-run the Junie run with
claude-opus-4-6as the main model. Junie methodology: We follow Junie's default guidance and run in non-interactive mode:--skip-update-check --output-format=json. In our default setup, Junie usedclaude-opus-4-6,gpt-4.1-mini-2025-04-14, andgpt-4.1-2025-04-14for summarization. - [Update] Cursor methodology: We run Cursor with Composer 2 as the primary model:
-p --force --output-format=stream-json --model=composer-2 --yolo --endless-retries.
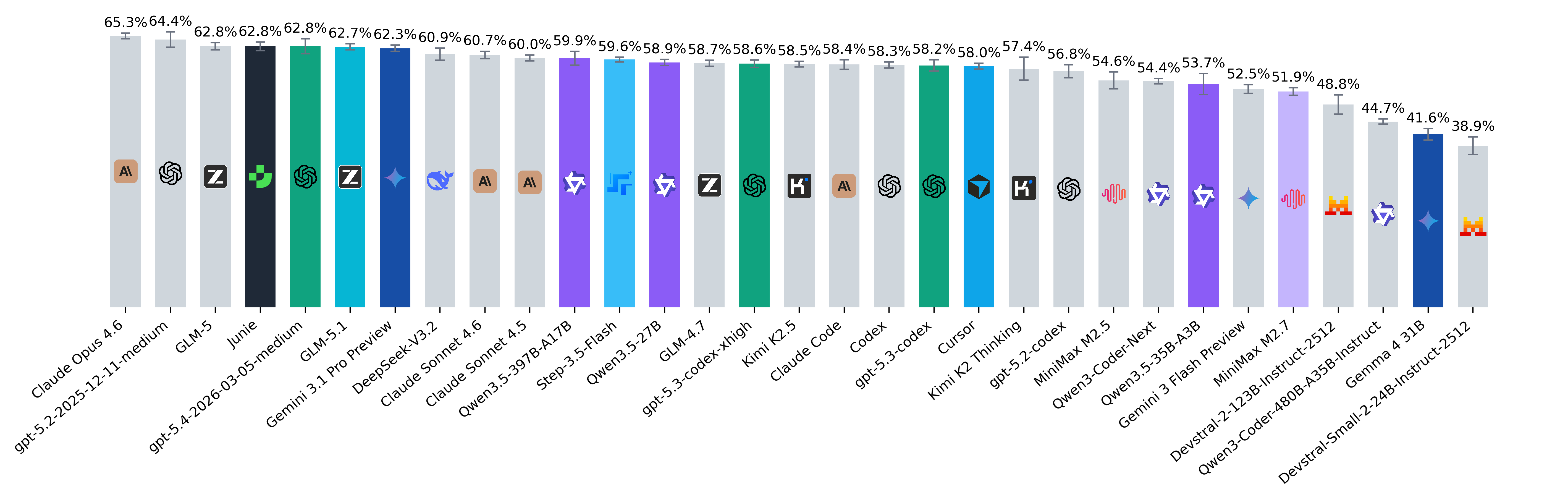
January 2026
- [Update] Junie methodology: We follow Junie's default guidance and run in non-interactive mode:
junie --skip-update-check --output-format=json. In our default setup, Junie usedgemini-3-flash-preview,gpt-4.1-mini-2025-04-14, andgpt-4.1-2025-04-14for summarization. - Claude Opus 4.6 has claimed the #1 spot on the leaderboard. The relatively low SEM suggests stable performance on this benchmark compared to several others.
- Claude Code pass@5 is higher than that of all other models.
- gpt-5.2-codex is an extremely token-efficient model, consuming fewer tokens than any other model with similar capability.
- Kimi K2 Thinking (Best Pass@1), GLM-5 (Minimum Tokens per Problem), and Qwen3-Coder-Next (Best Pass@5) are leading the open-source rankings this month. Notably, open-source models are catching up with powerful closed-source models like gpt-5.2-codex and Opus 4.5.
- Qwen3-Coder-Next shows notably strong performance despite having ~3B active parameters, making it a compelling frontier option for cost-effective agent deployments. However, many hosted providers do not support token/prefix caching for this model, which can materially reduce efficiency in agentic workflows with repeated context. To account for this, our Qwen3 price estimates were computed using vLLM, treating cached tokens as input tokens in the cost calculation. Under this setup, the average cost per problem is close to GLM-5. Notably, by pass@5, this model ranks in the top 2.
- Claude Code methodology: We follow Anthropic’s default guidance and run in headless mode:
--model=opus --allowedTools="Bash,Read,Write,Edit" --permission-mode acceptEdits --output-format stream-json --verbose. We also setANTHROPIC_DEFAULT_OPUS_MODEL=claude-opus-4-6to use Opus 4.6 as the primary model. - Codex methodology: We run Codex with gpt-5.2-codex as the primary model:
--model=gpt-5.2-codex --yolo --json. We plan to add gpt-5.3-codex once API access becomes available. - Although Claude Code and Codex support non-interactive execution, their default ergonomics are still “developer-in-the-loop,” so truly headless behavior requires explicit automation-oriented flags (structured output, non-interactive prompt mode, and permission/tool policies).
- The latest MiniMax M2.5 is a powerful model that competes with the best open-source models while being among the cheapest options (cost per problem: only $0.09).
- Kimi shows a clear split between “thinking” and base variants: Kimi K2 Thinking (43.8%) substantially outperforms Kimi K2.5 (37.9%) on this benchmark. In practice, this quality gain may come with different token and latency profiles, so the best choice can depend on token budgets and time-to-solution requirements.
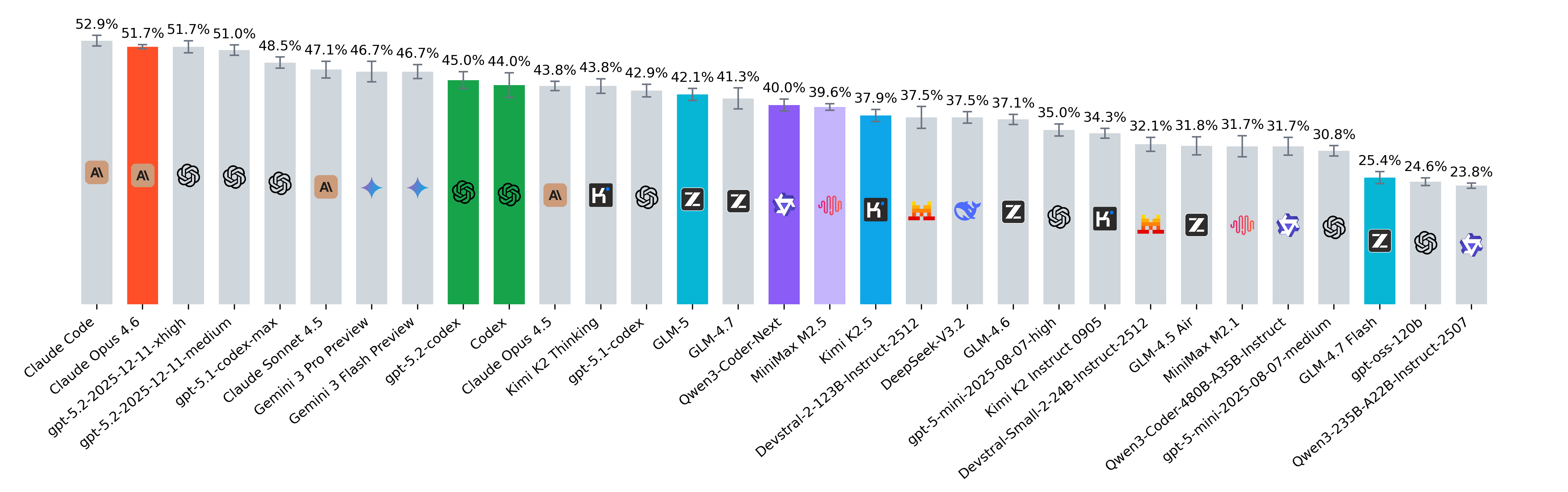
December 2025
- In our evaluations, Gemini 3 Flash Preview slightly outperformed Gemini 3 Pro Preview on pass@1 (57.6% vs 56.5%), despite being the smaller and cheaper model. This mirrors Google’s own SWE-bench Verified results and its description of Flash as a model designed for coding and agentic workflows that emphasize rapid, iterative development and fast feedback loops.
- GLM-4.7 stands out as the strongest open-source model on our leaderboard, ranking alongside closed models like GPT-5.1-codex.
- GPT-OSS-120B saw a large jump in performance when run in high-effort reasoning mode, nearly doubling its resolved rate compared to its standard configuration, highlighting how much inference-time scaling can matter.
- We hypothesize that Claude Code's ranking relative to Claude Opus 4.5 may be influenced by its reliance on Claude Haiku 4.5 for executing specific agent actions. It is possible that offloading frequent tasks to the smaller model limits overall performance, even with Opus providing high-level guidance.

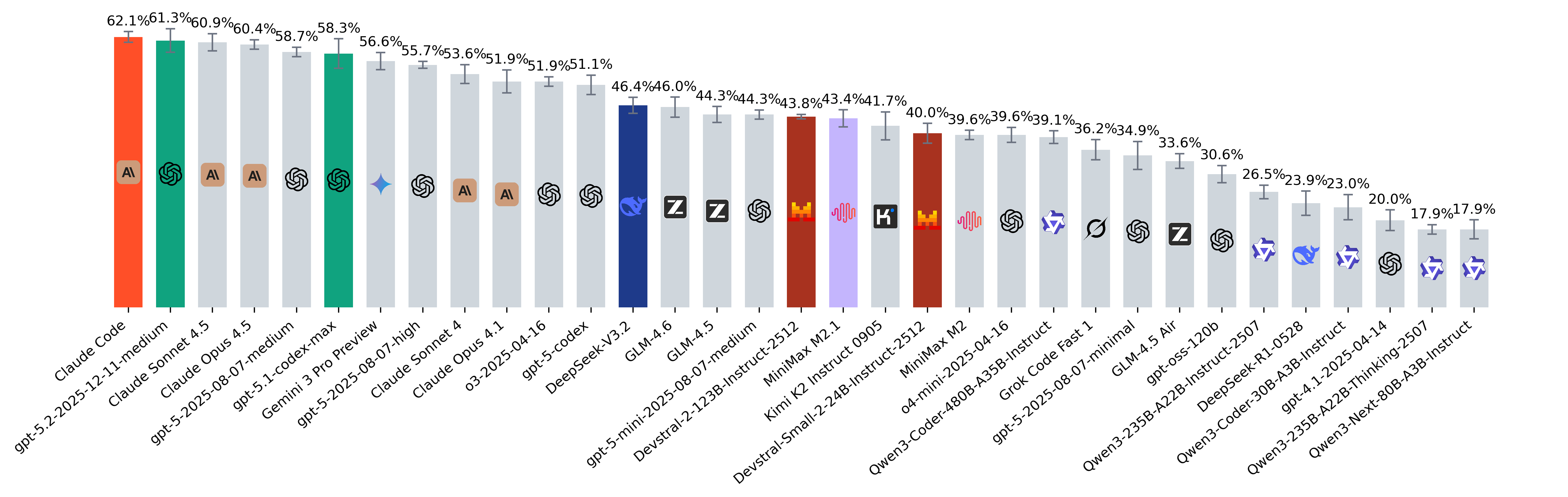
November 2025
- For Claude Code, we follow the default recommendation of running the agent in headless mode and using Opus 4.5 as the primary model:
--model=opus --allowedTools="Bash,Read" --permission-mode acceptEdits --output-format stream-json --verbose. This resulted in a mixed execution pattern where Opus 4.5 handles core reasoning and Haiku 4.5 is delegated auxiliary tasks. Across trajectories, ~30% of steps originate from Haiku, with the remaining majority from Opus 4.5. We use version 2.0.62 of Claude Code. In rare instances (1–2 out of 47 tasks), Claude Code attempts to use prohibited tools like WebFetch or user approval, resulting in timeouts and task failure. - GPT-5.2 reaches top-tier performance, matching Claude 4.5 Sonnet / Opus on agentic tasks while using significantly fewer tokens per problem, making it one of the most balanced models this month in terms of capability versus efficiency.
- Gemini 3 Pro shows a major leap in agentic performance compared to Gemini 2.5 Pro and firmly joins the group of leading models.
- DeepSeek v3.2 achieves SOTA among open-weight models. At the same time, it uses the highest number of tokens per problem across all evaluated models, suggesting a very expansive reasoning style.
- Devstral 2 123B model falls into the same performance range as other mid-tier systems, while the 24B variant remains relatively close despite a large size gap. Devstral 2 models are evaluated via self-hosted vLLM. Cost per Problem is omitted due to the lack of publicly available reference pricing.
- All OpenAI models are now evaluated via the Responses API with keeping reasoning items in context.
- As in previous updates, we also track least frequently solved problems. This month, the hardest tasks are tobymao/sqlglot-6374 and sympy/sympy-28660.
October 2025
- [Update] While the cumulative Pass@5 across all models stands at 72.5%, the combination of Opus 4.5, GPT-5 Codex, and Gemini 3 Pro reached 58.8%. Notably, marimo-team/marimo-6629, getmoto/moto-9350 and piskvorky/smart_open-892 were the least frequently solved problems.
- [Update] We re-ran the MiniMax M2 model through the official API platform with token caching enabled, which is not supported on OpenRouter for now. We also added a new column, Cached Tokens, which shows the average percentage of cached tokens in the token usage.
- [Update] Claude Opus 4.5 has claimed the #1 spot on the leaderboard. Remarkably for a flagship model, it is only slightly more expensive per problem than Sonnet 4.5 (1.15 vs 0.98).
- Claude Sonnet 4.5 delivers the strongest pass@1 and pass@5 results, and it uses more tokens per problem than gpt-5-medium and gpt-5-high despite not running in reasoning mode. This indicates that Sonnet 4.5 adapts its reasoning depth internally and uses its capacity efficiently.
- GPT-5 variants differ in how often they invoke reasoning: gpt-5-medium uses it in ~58% of steps (avg. 714 tokens), while gpt-5-high increases this to ~62% (avg. 1053 tokens). However, this additional reasoning does not translate into better task-solving ability in our setup: gpt-5-medium achieves a pass@5 of 49.0%, compared to 47.1% for gpt-5-high.
- MiniMax M2 is the most cost-efficient open-source model among the top performers. Its pricing is $0.255 / $1.02 per 1M input/output tokens, whereas gpt-5-codex costs $1.25 / $10.00 – with cached input available at just $0.125. In agentic workflows, where large trajectory prefixes are reused, this cache advantage can make models with cheap cache reads more beneficial even if their raw input/output prices are higher. In case of gpt-5-codex, it has approximately the same Cost per Problem as MiniMax M2 ($0.51 vs $0.44), being yet much more powerful.
- GLM-4.6 reaches the agent’s maximum step limit (80 steps in our setup) roughly twice as often as GLM-4.5. This suggests its performance may be constrained by the step budget, and increasing the limit could potentially improve its resolved rate.
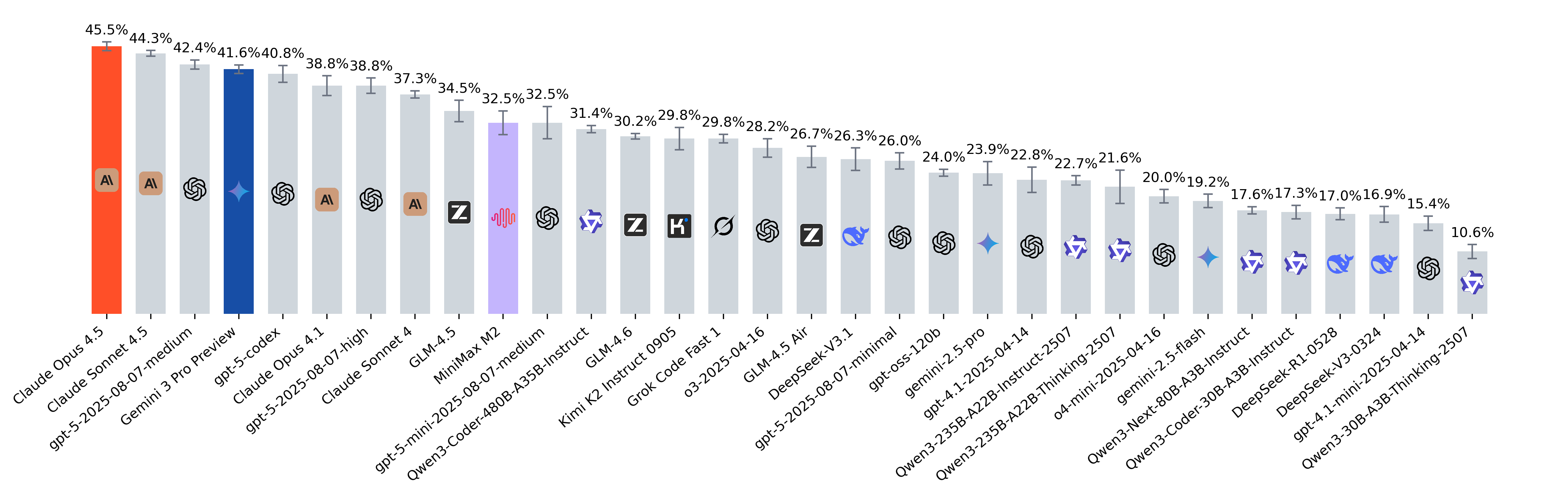
September 2025
- Claude Sonnet 4.5 demonstrated notably strong generalization and problem coverage, achieving the highest pass@5 (55.1%) and uniquely solving several instances that no other model on the leaderboard managed to resolve: python-trio/trio-3334, cubed-dev/cubed-799, canopen-python/canopen-613.
- Grok Code Fast 1 and gpt-oss-120b stand out as ultra-efficient budget options, delivering around 29%–30% resolved rate for only $0.03–$0.04 per problem.
- We observed that Anthropic models (e.g., Claude Sonnet 4) do not use caching by default, unlike other frontier models. Proper use of caching dramatically reduces inference costs – for instance, the average per-problem cost for Claude Sonnet 4 dropped from $5.29 in our August release to just $0.91 in September. All Anthropic models in the current September release were evaluated with caching enabled, ensuring cost figures are now directly comparable to other frontier models.
- All models on the leaderboard were evaluated using the ChatCompletions API, except for gpt-5-codex and gpt-oss-120b, which are only accessible via the Responses API. The Responses API natively supports reasoning models and allows linking to previous responses through unique references. This mechanism leverages the model's internal reasoning context from earlier steps – a feature turned out to be beneficial for agentic systems that require multi-step reasoning continuity.
- We also evaluated gpt-5-medium with reasoning context reuse enabled via the Responses API, where it achieved a resolved rate of 41.2% and pass@5 of 51%. However, to maintain fairness, we excluded these results from the leaderboard since other reasoning-capable models currently do not have reasoning-context reuse enabled within our evaluation framework. We're interested in evaluating all frontier models with preserving reasoning context from earlier steps to validate how their performance changes.
- In our evaluation, we observed that gpt-5-high performed worse than gpt-5-medium. We initially attributed this to the agent's maximum step limit, theorizing that gpt-5-high requires more steps to run tests and check corner cases. However, doubling the max_step_limit from its default of 80 to 160 yielded only a slight performance increase (pass@1: 36.3% -> 38.3%, pass@5: 46.9% -> 48.9%). An alternative hypothesis, which we will validate shortly, is that gpt-5-high benefits especially from using its previous reasoning steps.
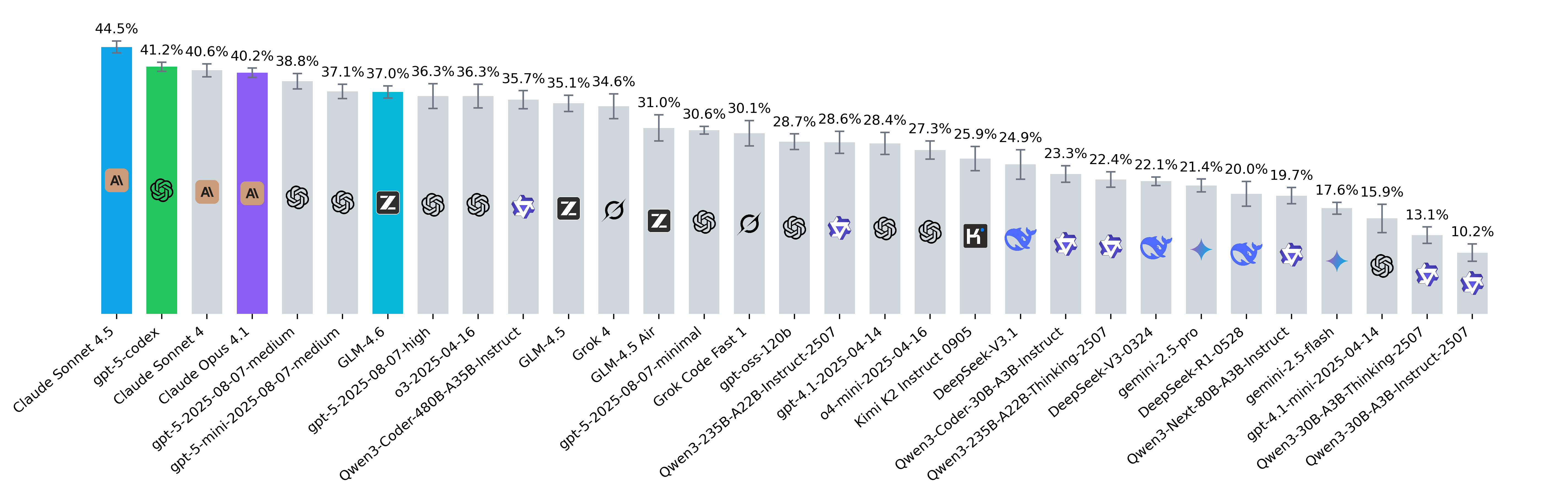
August 2025
- Kimi-K2 0915 has grown significantly (34.6% -> 42.3% increase in resolved rate) and is now in the top 3 open-source models.
- DeepSeek V3.1 also improved, though less dramatically. At the same time, the number of tokens produced has grown almost 4x.
- Qwen3-Next-80B-A3B-Instruct, despite not being trained directly for coding, performs on par with the 30B-Coder. To reflect models speed, we’re also thinking about how best to report efficiency metrics such as tokens/sec on the leaderboard.
- Finally, Grok 4: the frontier model from xAI has now entered the leaderboard and is among the top performers.
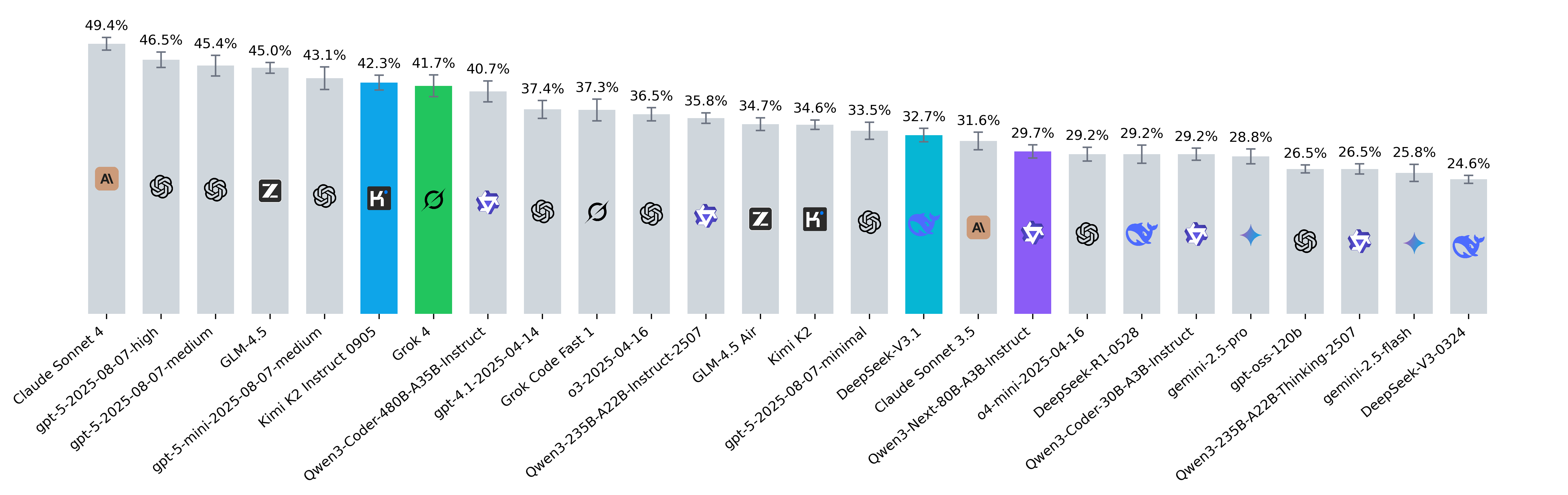
Insights
Rank | Model | Resolved Rate (%) | Resolved Rate SEM (±) | Pass@5 (%) | Cost per Problem ($) | Tokens per Problem | Cached Tokens (%) |
|---|---|---|---|---|---|---|---|
| 1 | gpt-5.5-2026-04-23-xhigh | 62.7% | 0.91% | 70.0% | $2.25 | 2,120,660 | 90.0% |
| 2 | Codex | 60.4% | 1.37% | 71.8% | $1.75 | 1,898,131 | 92.5% |
| 3 | Claude Code | 59.6% | 1.98% | 72.7% | $1.74 | 1,878,248 | 93.6% |
| 4 | gpt-5.5-2026-04-23-medium | 58.9% | 0.78% | 70.0% | $0.98 | 708,418 | 83.5% |
| 5 | Claude Opus 4.8-xhigh | 56.4% | 1.29% | 67.3% | $2.02 | 2,479,387 | 95.5% |
| 6 | gpt-5.4-2026-03-05-medium | 54.9% | 1.02% | 70.9% | $0.60 | 834,452 | 83.5% |
| 7 | Claude Opus 4.7-high | 53.1% | 1.45% | 66.4% | $1.32 | 1,526,135 | 94.2% |
| 8 | Cursor | 53.0% | 0.53% | 64.5% | $0.23 | 1,031,653 | 98.7% |
| 9 | Claude Sonnet 4.6-high | 51.3% | 0.55% | 63.6% | $1.29 | 2,644,577 | 95.6% |
| 10 | Gemini 3.1 Pro Preview | 51.1% | 1.20% | 66.4% | $0.75 | 1,545,445 | 80.1% |
| 11 | GLM-5.1 | 50.7% | 0.93% | 65.5% | $0.94 | 2,664,001 | 91.8% |
| 12 | Claude Opus 4.6-high | 47.8% | 1.37% | 60.9% | $1.53 | 1,828,649 | 93.6% |
| 13 | Kimi K2.6 | 46.5% | 1.27% | 64.5% | $0.61 | 2,466,977 | 90.4% |
| 14 | GLM-4.7 | 38.2% | 0.86% | 59.1% | $0.39 | 2,256,182 | 86.4% |
| 15 | Claude Opus 4.1 | N/A | N/A | N/A | N/A | N/A | N/A |
| 16 | Claude Opus 4.5 | N/A | N/A | N/A | N/A | N/A | N/A |
| 17 | Claude Sonnet 3.5 | N/A | N/A | N/A | N/A | N/A | N/A |
| 18 | Claude Sonnet 4 | N/A | N/A | N/A | N/A | N/A | N/A |
| 19 | Claude Sonnet 4.5 | N/A | N/A | N/A | N/A | N/A | N/A |
| 20 | DeepSeek-R1-0528 | N/A | N/A | N/A | N/A | N/A | N/A |
| 21 | DeepSeek-V3 | N/A | N/A | N/A | N/A | N/A | N/A |
| 22 | DeepSeek-V3-0324 | N/A | N/A | N/A | N/A | N/A | N/A |
| 23 | DeepSeek-V3-0324 | N/A | N/A | N/A | N/A | N/A | N/A |
| 24 | DeepSeek-V3.1 | N/A | N/A | N/A | N/A | N/A | N/A |
| 25 | DeepSeek-V3.2 | N/A | N/A | N/A | N/A | N/A | N/A |
| 26 | Devstral-2-123B-Instruct-2512 | N/A | N/A | N/A | N/A | N/A | N/A |
| 27 | Devstral-Small-2-24B-Instruct-2512 | N/A | N/A | N/A | N/A | N/A | N/A |
| 28 | Devstral-Small-2505 | N/A | N/A | N/A | N/A | N/A | N/A |
| 29 | Gemini 3 Flash Preview | N/A | N/A | N/A | N/A | N/A | N/A |
| 30 | Gemini 3 Pro Preview | N/A | N/A | N/A | N/A | N/A | N/A |
| 31 | gemini-2.0-flash | N/A | N/A | N/A | N/A | N/A | N/A |
| 32 | gemini-2.0-flash | N/A | N/A | N/A | N/A | N/A | N/A |
| 33 | gemini-2.5-flash | N/A | N/A | N/A | N/A | N/A | N/A |
| 34 | gemini-2.5-flash-preview-05-20 no-thinking | N/A | N/A | N/A | N/A | N/A | N/A |
| 35 | gemini-2.5-flash-preview-05-20 no-thinking | N/A | N/A | N/A | N/A | N/A | N/A |
| 36 | gemini-2.5-pro | N/A | N/A | N/A | N/A | N/A | N/A |
| 37 | Gemma 4 31B | N/A | N/A | N/A | N/A | N/A | N/A |
| 38 | gemma-3-27b-it | N/A | N/A | N/A | N/A | N/A | N/A |
| 39 | GLM-4.5 | N/A | N/A | N/A | N/A | N/A | N/A |
| 40 | GLM-4.5 Air | N/A | N/A | N/A | N/A | N/A | N/A |
| 41 | GLM-4.6 | N/A | N/A | N/A | N/A | N/A | N/A |
| 42 | GLM-4.7 Flash | N/A | N/A | N/A | N/A | N/A | N/A |
| 43 | GLM-5 | N/A | N/A | N/A | N/A | N/A | N/A |
| 44 | GLM-5.1 | N/A | N/A | N/A | N/A | N/A | N/A |
| 45 | gpt-4.1-2025-04-14 | N/A | N/A | N/A | N/A | N/A | N/A |
| 46 | gpt-4.1-2025-04-14 | N/A | N/A | N/A | N/A | N/A | N/A |
| 47 | gpt-4.1-mini-2025-04-14 | N/A | N/A | N/A | N/A | N/A | N/A |
| 48 | gpt-4.1-mini-2025-04-14 | N/A | N/A | N/A | N/A | N/A | N/A |
| 49 | gpt-4.1-nano-2025-04-14 | N/A | N/A | N/A | N/A | N/A | N/A |
| 50 | gpt-5-2025-08-07-high | N/A | N/A | N/A | N/A | N/A | N/A |
| 51 | gpt-5-2025-08-07-medium | N/A | N/A | N/A | N/A | N/A | N/A |
| 52 | gpt-5-2025-08-07-minimal | N/A | N/A | N/A | N/A | N/A | N/A |
| 53 | gpt-5-codex | N/A | N/A | N/A | N/A | N/A | N/A |
| 54 | gpt-5-mini-2025-08-07-high | N/A | N/A | N/A | N/A | N/A | N/A |
| 55 | gpt-5-mini-2025-08-07-medium | N/A | N/A | N/A | N/A | N/A | N/A |
| 56 | gpt-5.1-codex | N/A | N/A | N/A | N/A | N/A | N/A |
| 57 | gpt-5.1-codex-max | N/A | N/A | N/A | N/A | N/A | N/A |
| 58 | gpt-5.2-2025-12-11-medium | N/A | N/A | N/A | N/A | N/A | N/A |
| 59 | gpt-5.2-2025-12-11-xhigh | N/A | N/A | N/A | N/A | N/A | N/A |
| 60 | gpt-5.2-codex | N/A | N/A | N/A | N/A | N/A | N/A |
| 61 | gpt-5.3-codex | N/A | N/A | N/A | N/A | N/A | N/A |
| 62 | gpt-5.3-codex-xhigh | N/A | N/A | N/A | N/A | N/A | N/A |
| 63 | gpt-oss-120b | N/A | N/A | N/A | N/A | N/A | N/A |
| 64 | gpt-oss-120b-high | N/A | N/A | N/A | N/A | N/A | N/A |
| 65 | gpt-oss-20b | N/A | N/A | N/A | N/A | N/A | N/A |
| 66 | Grok 4 | N/A | N/A | N/A | N/A | N/A | N/A |
| 67 | Grok Code Fast 1 | N/A | N/A | N/A | N/A | N/A | N/A |
| 68 | horizon-alpha | N/A | N/A | N/A | N/A | N/A | N/A |
| 69 | horizon-beta | N/A | N/A | N/A | N/A | N/A | N/A |
| 70 | Junie | N/A | N/A | N/A | N/A | N/A | N/A |
| 71 | Kimi K2 | N/A | N/A | N/A | N/A | N/A | N/A |
| 72 | Kimi K2 Instruct 0905 | N/A | N/A | N/A | N/A | N/A | N/A |
| 73 | Kimi K2 Thinking | N/A | N/A | N/A | N/A | N/A | N/A |
| 74 | Kimi K2.5 | N/A | N/A | N/A | N/A | N/A | N/A |
| 75 | Llama-3.3-70B-Instruct | N/A | N/A | N/A | N/A | N/A | N/A |
| 76 | Llama-4-Maverick-17B-128E-Instruct | N/A | N/A | N/A | N/A | N/A | N/A |
| 77 | Llama-4-Scout-17B-16E-Instruct | N/A | N/A | N/A | N/A | N/A | N/A |
| 78 | MiniMax M2 | N/A | N/A | N/A | N/A | N/A | N/A |
| 79 | MiniMax M2.1 | N/A | N/A | N/A | N/A | N/A | N/A |
| 80 | MiniMax M2.5 | N/A | N/A | N/A | N/A | N/A | N/A |
| 81 | MiniMax M2.7 | N/A | N/A | N/A | N/A | N/A | N/A |
| 82 | o3-2025-04-16 | N/A | N/A | N/A | N/A | N/A | N/A |
| 83 | o4-mini-2025-04-16 | N/A | N/A | N/A | N/A | N/A | N/A |
| 84 | Qwen2.5-72B-Instruct | N/A | N/A | N/A | N/A | N/A | N/A |
| 85 | Qwen2.5-Coder-32B-Instruct | N/A | N/A | N/A | N/A | N/A | N/A |
| 86 | Qwen3-235B-A22B | N/A | N/A | N/A | N/A | N/A | N/A |
| 87 | Qwen3-235B-A22B no-thinking | N/A | N/A | N/A | N/A | N/A | N/A |
| 88 | Qwen3-235B-A22B thinking | N/A | N/A | N/A | N/A | N/A | N/A |
| 89 | Qwen3-235B-A22B-Instruct-2507 | N/A | N/A | N/A | N/A | N/A | N/A |
| 90 | Qwen3-235B-A22B-Thinking-2507 | N/A | N/A | N/A | N/A | N/A | N/A |
| 91 | Qwen3-30B-A3B-Instruct-2507 | N/A | N/A | N/A | N/A | N/A | N/A |
| 92 | Qwen3-30B-A3B-Thinking-2507 | N/A | N/A | N/A | N/A | N/A | N/A |
| 93 | Qwen3-32B | N/A | N/A | N/A | N/A | N/A | N/A |
| 94 | Qwen3-32B no-thinking | N/A | N/A | N/A | N/A | N/A | N/A |
| 95 | Qwen3-32B thinking | N/A | N/A | N/A | N/A | N/A | N/A |
| 96 | Qwen3-Coder-30B-A3B-Instruct | N/A | N/A | N/A | N/A | N/A | N/A |
| 97 | Qwen3-Coder-480B-A35B-Instruct | N/A | N/A | N/A | N/A | N/A | N/A |
| 98 | Qwen3-Coder-Next | N/A | N/A | N/A | N/A | N/A | N/A |
| 99 | Qwen3-Next-80B-A3B-Instruct | N/A | N/A | N/A | N/A | N/A | N/A |
| 100 | Qwen3.5-27B | N/A | N/A | N/A | N/A | N/A | N/A |
| 101 | Qwen3.5-35B-A3B | N/A | N/A | N/A | N/A | N/A | N/A |
| 102 | Qwen3.5-397B-A17B | N/A | N/A | N/A | N/A | N/A | N/A |
| 103 | Step-3.5-Flash | N/A | N/A | N/A | N/A | N/A | N/A |
News
- [2026-05-28]:
- Added new models to the leaderboad: Claude Opus 4.8.
- [2026-05-27]:
- Added new models to the leaderboad: gpt-5.5-2026-04-23-xhigh, gpt-5.5-2026-04-23-medium, gpt-5.4-2026-03-05-medium, Claude Opus 4.7, and Kimi K2.6.
- [2026-04-19]:
- Re-run the Junie with Claude Opus 4.6 as the primary model.
- [2026-04-15]:
- Added new models to the leaderboad: GLM-5.1, Qwen3.5-27B, Cursor, Gemma 4 31B and MiniMax M2.7.
- [2026-03-20]:
- Added new models to the leaderboard: gpt-5.4-2026-03-05-medium, Gemini 3.1 Pro Preview, Claude Sonnet 4.6, Qwen3.5-397B-A17B, gpt-5.3-codex-xhigh, gpt-5.3-codex and Qwen3.5-35B-A3B
- Deprecated following models: gpt-5.2-2025-12-11-xhigh, gpt-5.1-codex-max, gpt-5.1-codex, gpt-5-mini-2025-08-07-high, gpt-5-mini-2025-08-07-medium, Qwen3-235B-A22B-Instruct-2507, DeepSeek-R1-0528, Qwen3-Coder-30B-A3B-Instruct, Qwen3-Next-80B-A3B-Instruct and Qwen3-30B-A3B-Instruct-2507.
- [2026-03-09]:
- Added reference evaluation for Junie CLI (highlighted in orange). See setup details in Insights.
- [2026-02-13]:
- Added new models to the leaderboard: Claude Opus 4.6, GLM-5, MiniMax M2.5, Codex, Qwen3-Coder-Next, GLM-4.7 Flash, gpt-5.2-codex, GLM-4.7 Flash.
- [2026-01-14]:
- Added new models to the leaderboard: gpt-5.2-2025-12-11-xhigh, gpt-5.1-codex, GLM-4.7, gpt-5-mini-2025-08-07-high, gpt-oss-120b-high, Kimi K2 Thinking.
- Deprecated following models: gpt-5-2025-08-07-medium, gpt-5-2025-08-07-high, Claude Sonnet 4, Claude Opus 4.1, o3-2025-04-16, gpt-5-codex, GLM-4.5, o4-mini-2025-04-16, gpt-5-2025-08-07-minimal, gpt-4.1-2025-04-14, Qwen3-235B-A22B-Thinking-2507, gpt-4.1-mini-2025-04-14, Qwen3-30B-A3B-Thinking-2507.
- [2025-12-22]:
- Added new model to the leaderboard: MiniMax M2.1.
- [2025-12-17]:
- Added new models to the leaderboard: gpt-5.1-codex-max, gpt-5.2-2025-12-11-medium, Devstral-2-123B-Instruct-2512, Devstral-Small-2-24B-Instruct-2512, DeepSeek-V3.2.
- Added reference evaluation for Claude Code (highlighted in orange). See setup details in Insights.
- Deprecated following models: gemini-2.5-pro, gemini-2.5-flash, DeepSeek-V3.1.
- [2025-12-08]:
- Added new model to the leaderboard: Gemini 3 Pro Preview.
- [2025-12-05]:
- Introduced Cached Tokens column.
- [2025-11-25]:
- Added new model to the leaderboard: Claude Opus 4.5.
- [2025-11-13]:
- Added new model to the leaderboard: MiniMax M2.
- [2025-10-28]:
- Added new model to the leaderboard: GLM-4.6.
- [2025-10-09]:
- Added new models to the leaderboard: Claude Sonnet 4.5, gpt-5-codex, Claude Opus 4.1, Qwen3-30B-A3B-Thinking-2507 and Qwen3-30B-A3B-Instruct-2507.
- Added a new Insights section providing analysis and key takeaways from recent model and data releases.
- Deprecated following models:
- Text: Llama-3.3-70B-Instruct, Llama-4-Maverick-17B-128E-Instruct, gemma-3-27b-it and Qwen2.5-72B-Instruct.
- Tools: Claude Sonnet 3.5, Kimi K2, gemini-2.0-flash, Qwen3-235B-A22B and Qwen3-32B.
- [2025-09-17]:
- Added new models to the leaderboard: Grok 4, Kimi K2 Instruct 0905, DeepSeek-V3.1 and Qwen3-Next-80B-A3B-Instruct.
- [2025-09-04]:
- Added new models to the leaderboard: GLM-4.5, GLM-4.5 Air, Grok Code Fast 1, Kimi K2, gpt-5-mini-2025-08-07-medium, gpt-oss-120b and gpt-oss-20b.
- Introduced Cost per Problem and Tokens per Problem columns.
- Added links to the pull requests within the selected time window. You can review them via the
Inspectbutton. - Deprecated following models:
- Text: DeepSeek-V3, DeepSeek-V3-0324, Devstral-Small-2505, gemini-2.0-flash, gpt-4.1-2025-04-14, gpt-4.1-mini-2025-04-14, gpt-4.1-nano-2025-04-14, Llama-4-Scout-17B-16E-Instruct and Qwen2.5-Coder-32B-Instruct.
- Tools: horizon-alpha and horizon-beta.
- [2025-08-12]: Added new models to the leaderboard: gpt-5-medium-2025-08-07, gpt-5-high-2025-08-07 and gpt-5-minimal-2025-08-07.
- [2025-08-02]: Added new models to the leaderboard: Qwen3-Coder-30B-A3B-Instruct, horizon-beta.
- [2025-07-31]:
- Added new models to the leaderboard: gemini-2.5-pro, gemini-2.5-flash, o4-mini-2025-04-16, Qwen3-Coder-480B-A35B-Instruct, Qwen3-235B-A22B-Thinking-2507, Qwen3-235B-A22B-Instruct-2507, DeepSeek-R1-0528 and horizon-alpha.
- Deprecated models: gemini-2.5-flash-preview-05-20 no-thinking.
- Updated demo format: tool calls are now shown as distinct assistant and tool messages.
- [2025-07-11]: Released Docker images for all leaderboard problems and published a dedicated HuggingFace dataset containing only the problems used in the leaderboard.
- [2025-07-10]: Added models performance chart and evaluations on June data.
- [2025-06-12]: Added tool usage support, evaluations on May data and new models: Claude Sonnet 3.5/4 and o3.
- [2025-05-22]: Added Devstral-Small-2505 to the leaderboard.
- [2025-05-21]: Added new models to the leaderboard: gpt-4.1-mini-2025-04-14, gpt-4.1-nano-2025-04-14, gemini-2.0-flash and gemini-2.5-flash-preview-05-20.